Quadruped Robots Projects

AMP for Go1
Implemented the Adversarial Motion Priors (AMP) framework in IsaacGym, leveraging real quadruped MoCap data to train the Go1 robot to acquire natural, biomechanically plausible gaits. Validated the policy via Sim2Sim transfer to MuJoCo, and successfully deployed on real hardware — eliminating motor jitter caused by communication latency through jerk penalty terms and command smoothing filters.
1. Sim2Sim

2. Sim2Real



Quadruped Locomotion and Navigation in Wild
Developed a RL-based locomotion policy in IsaacLab using elevation map observations (height scan dots) decoded from real-time dense terrain maps built by integrating ETH Elevation Mapping with LiDAR odometry. Achieved robust stair-climbing and long-range autonomous navigation on the Go2 platform via a pre-collected trajectory tracking strategy, with terrain noise modeling bridging the sim-to-real gap.
1. Sim2Sim

2. Elevation Map

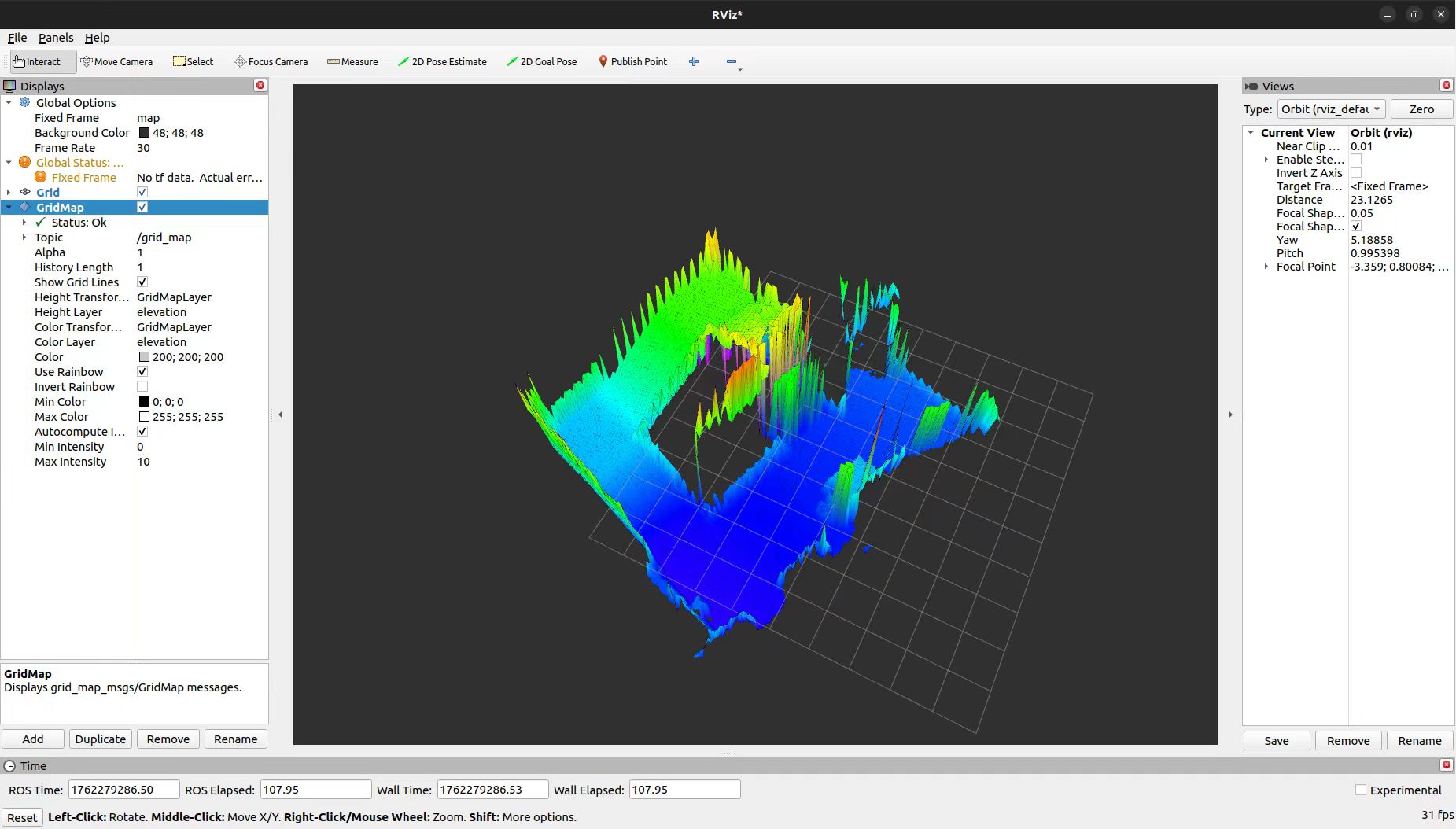
3. Real World

Humanoid Locomotion on Stairs
Built a modular G1 humanoid training environment in Isaac Lab with diverse unstructured terrains (stairs, slopes, rough ground) and terrain curriculum learning to progressively guide the policy from flat-ground walking to complex terrain adaptation. Validated across simulators via MuJoCo Sim2Sim with actuator parameter alignment, then deployed on G1 hardware — addressing hard landing issues through periodic gait functions, contact force penalties, and domain randomization to improve smoothness and disturbance rejection.